Stanco di perdere ore nella trascrizione audio? Ti sei mai chiesto se l’intelligenza artificiale può convertire i tuoi file audio in testo senza stress? Dopo averti parlato di Whisper AI (di Open AI), oggi voglio presentarti WhisperX (sviluppato da Max Bain), la possibile evoluzione e soluzione a tutti i tuoi (e miei) problemi. In questa guida dettagliata, esploreremo come utilizzare WhisperX e metteremo a confronto le sue caratteristiche con Whisper AI.
Introduzione
Se questa pagina ti sembra un treno che passa veloce e a te sembra di avere una faccia da mucca mentre lo leggi, ti suggerisco di proseguire la lettura con ordine, senza saltare paragrafi.
Se invece sei skillato e brami WhisperX perché sai già di cosa parlo, allora skippa direttamente alla guida all’installazione più avanti.
Chi è Max Bain e cos’è WhisperX
Max Bain, è un giovane post Doc attualmente ricercatore presso Reka AI, dove studia i modelli linguistici multimodali di grandi dimensioni. Il suo ultimo progetto si chiama WhisperX e rappresenta l’evoluzione di Whisper AI. Per gli appassionati di pubblicazioni scientifiche: [2303.00747] WhisperX: Time-Accurate Speech Transcription of Long-Form Audio (arxiv.org). Per tutti gli altri queste parole potrebbero sembrare supercazzole, ma volendole ridurre in una sola frase: è possibile ottenere una trascrizione audio veloce, precisa e gratuita usando l’intelligenza artificiale.
WhisperX è un potente strumento di trascrizione audio basato su avanzate tecnologie di riconoscimento vocale, tra cui:
- Phoneme-Based ASR: una suite di modelli messi a punto per riconoscere la più piccola unità del discorso che distingue una parola da un’altra, ad esempio l’elemento p in “tap”. Un modello di esempio popolare è wav2vec2.0;
- Forced Alignment: si riferisce al processo mediante il quale le trascrizioni ortografiche vengono allineate alle registrazioni audio per generare automaticamente la segmentazione;
- Voice Activity Detection (VAD): permette di capire se è presente voce umana o meno;
- Speaker Diarization: il processo di porzionare il flusso audio contenente voce umana in segmenti omogenei e di attribuirli ad ogni speaker.
Come molti dei software per l’intelligenza artificiale in fase di sviluppo, il suo uso può non esser intuitivo per chi come me e te si trova con ore di audio da sbobinare. Se per Whisper AI, oltre alla possibilità di usare il programma attraverso un termina e righe di comando, c’è una interfaccia user friendly (Whisper AI Desktop), per WhisperX questo non è attualmente ancora disponibile. Ma non temere, se seguirai questa guida, sarai in grado di portare a casa la pagnotta.
Puoi saperne di più su di lui e le sue altre creazioni visitando il suo sito ufficiale: Max Bain.
Vantaggi di WhisperX rispetto a Whisper AI
WhisperX si presenta come una soluzione all’avanguardia per la trascrizione audio. Vediamo dopo come sfruttare appieno le sue potenzialità, ma ora, approfondiamo i vantaggi di WhisperX rispetto a Whisper AI.
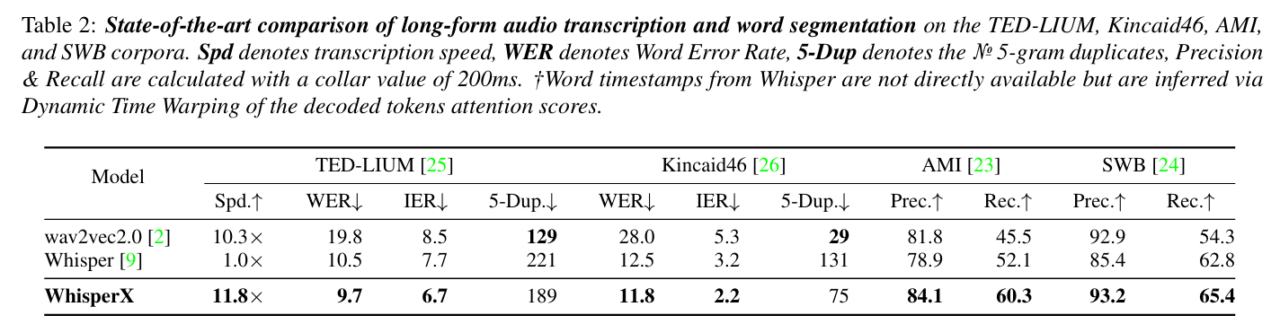
Citando sempre il paper di Max Bain:
[…] We show that the proposed VAD Cut & Merge preprocessing reduces hallucination and repetition, enabling within-audio batched transcription, resulting in a twelve-fold speed increase without sacrificing transcription quality. Further, we show that the transcribed segments can be forced aligned with a phoneme model, providing accurate word-level seg mentations with minimal inference overhead and resulting in time-accurate transcriptions benefitting a range of applications (e.g. subtitling, diarisation etc.)
Fonte: [2303.00747] WhisperX: Time-Accurate Speech Transcription of Long-Form Audio (arxiv.org)
In soldoni: 12 volte più veloce rispetto a WhisperX (sino a 70 volte rispetto al real time), riduzione dei fenomeni allucinatori, maggiore fedeltà al timestamp, possibilità di distinguere più interlocutori e di usare il modello con meno risorse hardware necessarie (siccome si basa su Faster Whisper).
WhisperX: come usarlo
Il modo più veloce per implementare WhisperX è di usare il codice Colab condiviso online dallo youtuber 1Littlecoder.
Ti basterà fare 4 click e caricare il file per poter fare partire l’elaborazione (attenzione a inserire correttamente il nome del file anche nel comando prima di avviarlo!). Una volta terminata, potrai scaricare il file e tramutarlo in file di testo, magari togliendo anche i riferimenti temporali, come mostrato nella precedente guida su Whisper AI.
Il codice potrà esser aggiornato in futuro, e persino andare perso. Ma per tua fortuna potrai salvarlo sul tuo drive e fare si che non vada mai perso. Oltre a questo, l’unico vero svantaggio sta nell’attendere l’upload del file audio/video, che potrà rubarti un po’ di tempo nel caso di file di grandi dimensioni.
Alternativamente puoi installare tutto sul tuo pc in locale e per farlo dovrai:
- scaricare e installare CUDA Toolkit v 11.x (per usare la scheda video, GPU)
- scaricare e installare NVIDIA cuDNN v 8 (sempre per usare la GPU)
- aprire il terminale e digitare i seguenti codici:
conda create --name whisperx python=3.10conda activate whisperxconda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidiapip install git+https://github.com/m-bain/whisperx.gitpip install git+https://github.com/m-bain/whisperx.git --upgrade
Infine dovrebbe bastarti dare il comando finale (correggendo il nome del file, come anche sopra):
!whisperx 01.mp3 --model large-v2 --language it --output_dir . --batch_size 4 --align_model WAV2VEC2_ASR_LARGE_LV60K_960HDubbi o curiosità? Fammi sapere che risultati ottieni!